System Design Concepts for Product Managers — Part 2
This is a system design series for Product Managers who should have a high-level understanding of System Design.
We will first cover the basic concepts of System Design. This is part 2 of System Design. Stay tuned for future updates. You can find part_1 here.
Database Sharding
What is database Sharding?

Let’s start with an example, assume that you are a software engineer who is building a product for user management. You have to store the data of millions of users in your database. You have already realized that your user base is increasing rapidly; what you will do?
First, you will try to increase the capacity of the Database; increasing the capacity of the database make the search query to be slow. Then you realize that you need to do a partition of the data and query the database according to the request.
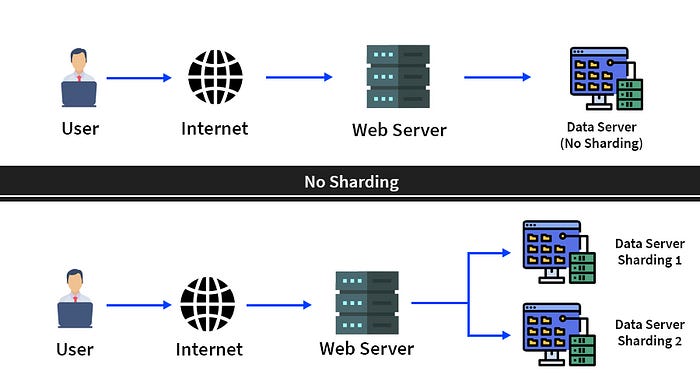
Database Sharding is the process of breaking up the large data into smaller chunks called shards; a shard is a horizontal data partition that contains a subset of the total data set.
Horizontal Vs Vertical partitioning
Let’s assume that you have 1 million user data in the database. The data is in the format of the table and have the following columns like Name, city, Phone number and income.
If we partition the data into four parts such that in one data, we have information about 1 million names; in another data, we have 1 million cities and so on. These are logically connected via the primary key. Such type of partition is known as vertical partitioning.
If we partition the data into four parts such that each data contains 0.25 millions of user data and combining all the data, we get the original 1 million data; this is known as horizontal partitioning, which is also known as Sharding. Sharding is a widely used technique for the scalability and availability of data.
Conceptually Sharding in the SQL and NoSQL databases remains the same, but since the structure of the data is different, so we need different strategies
Logical Shards vs Physical Shards
We have understood that the shard is nothing but a subset of the data. To understand the architecture of the data Sharding, we need to understand the term logical and physical shards.
So let’s say we have 4 million users, and we have partitioned them into four parts, each one with 1 million users. These shards(subset) are known as logical shards, and the database or the machine on which it resides are known as physical shards.
Algorithmic Sharding vs Dynamic Sharding
Algorithmic Sharding: Let’s say we have an application that wants to request data from the server; how will it know from which shard it has to fetch the data? In case there is a function on the client-side which takes some attributes of the data and decides which shard it has to go into, then it is known as algorithmic Sharding.
Dynamic Sharding: In Dynamic Sharding, there is a separate service that tells which shard the query (Read/Write) should route to. In Dynamic Sharding, the server-client talks to the service and the service will then route it to the correct place. Here we can add more shards if we want to expand into them; that’s why it is called Dynamic Sharding.
Advantage of Sharding
- Speed of the queries in the databases increases because we know in which logical partition we need to search. So, reducing latency, query optimization, and better performance are some of the advantages of Sharding
- We can put different shards into different locations, which can sometimes be very useful. In some applications, we can put the users into different shards depending on their location, which can play an important role in a search query, for example, Tinder.
- By Data Sharding, we can mitigate the risk of a single point of failure. Let’s say out of 4 shards on the server, if one of the servers goes down, in that case, we can still serve 75% of the users.
Disadvantages of Sharding
- Sharding is a complex technique, so if you haven’t done it correctly, in that case, it will put an unequal amount of data in shards.
- Once you have done Sharding, it is very difficult to combine the sharded data.
- Queries in which you have to search from the entire data then it becomes expensive operation because, in that case, it will go to all the shards, perform the operation and then combine the result from each shard and give back to the client.
Database Index
What are indexes?
The index is the data structure of the table of content which points us to the location where actual data resides; this works in a similar fashion like any table of content of the document works. It helps to increase the speed of the data retrieval. The indexing can be done in an ordered way called ordered indexing or can be done using hashing called hash indexing.
Proxy Server
We have already discussed Client-server architecture; if you haven’t checked, please read through this ARTICLE.
Some websites are blocked for students to access in college and many educational institutions. There you must have heard loosely about words like “use proxy” to bypass those rules. What does it mean by proxy?
Proxy servers are the intermediary between the client and the server; let’s say if the client doesn’t want / can’t talk to the server, then it can use a proxy server on his behalf.
Forward Proxy

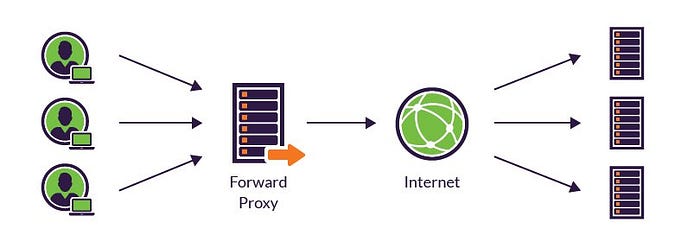
In the client-server architecture, if the proxy server sits on the client-side and talks to the server on the client’s behalf, then it is known as a forward proxy. It has multiple use cases like caching the data on the client-side or blocking access to some websites.
Reverse Proxy

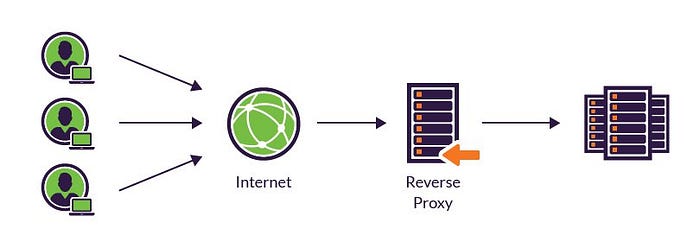
In the client-server architecture, if the proxy server sits on the server-side and talks to the client on the server’s behalf, then it is known as a reverse proxy. It has multiple use cases like caching the data on the server-side or blocking access to some websites. It can be used for traffic control and load balancing where the client doesn’t know the IP of the server but knows the IP for the proxy server.
-- TechnoManagers



Comments
Post a Comment